How our voicebot understands users without training? A three-level intent system
Launching a voicebot used to take weeks – testing, revisions, voice recordings, more testing… And even then, the accuracy during the first few days was often disappointing.
That all changed when we introduced a three-level intent recognition system, including GPT.
In this article, we share a real-world case:
- A voicebot launch in a brand-new language – with zero training
- No errors in the initial test calls
- Up to 98% accuracy on day one
- And no need to manually collect user phrase
How did we achieve this – and what did we learn along the way? Read on for the full breakdown.
The problem we set out to solve
Launching a new voicebot is always a challenge. Even with a perfectly written script and a good speech recognition engine, the main question remains: will the bot understand the user? In practice, unfortunately, the answer is often “sometimes” or “not right away.”
Each launch involved numerous steps: testing, gathering feedback, retraining intents. It took weeks. Teams spent resources organising calls with native speakers, involving different specialists, carrying out multiple checks and fixes. And even after all that, the bot often recognised user intents in only 60–65% of cases.
The worst part was the client’s first reaction. They would make a couple of test calls, say a phrase that didn’t follow the script – and hear in response: “Sorry, I didn’t understand.” At that moment, they lost trust in the entire product
We realised we couldn’t keep going like this. We wanted to launch a bot that understood users from day one – without prior training, without involving different kinds of specialists, and without unnecessary bureaucracy. And we found a way to do it.
How it used to be: a long, expensive and unreliable process – paid for by the client
Until recently, every conversational AI launch in our company followed a tried-and-tested, but exhausting routine. First, scriptwriters would prepare dialogues. Then, the team would ask native speakers in Slack: “Please call the new bot and just talk to it.” This took hours – both for developers and the implementation team.
Then came the next phase: testing with native speakers. We would assign them tasks, pay for the work, check the results. This process took about a week or more, including coordination, feedback and final corrections.
And even after all that preparation, the bot at launch showed an accuracy of no more than 60–65%. Why? Because every user expresses themselves differently. One says, “I’m having a problem with the printer,” another – “The printer won’t print,” and a third simply says, “It’s broken.” If those phrasings weren’t in the training set, the bot got confused.
Clients would call and try it themselves. But they aren’t real users – they speak differently, test the boundaries of the script, experiment. And the bot would often reply with something like, “Sorry, please repeat.” This would be followed by a call to us: “Why doesn’t it work?”
Then a new cycle would begin: internal edits, more testing, retraining intents, more native speakers. In the end, the launch could take three weeks or more – and by that point, the client’s enthusiasm might already have faded.
What we changed: a three-level intent recognition system
Everything changed when we introduced a three-level intent recognition system. It completely redefined how our voicebot understands the user and their queries – and became a turning point.
Level 1: Strict matches
This is the fastest and “dumbest” level. If the user says an exact phrase pre-defined in the script (e.g. “I like dogs”), the bot recognises it instantly – within milliseconds. This level relies on keywords and pre-written phrases.
Level 2: Trained customer intent model
If there’s no strict match, the phrase is passed to the built-in intent model we’ve used before. If this model is already trained, it can recognise around 75–80% of phrases. But if it’s a new bot, freshly launched, the model isn’t trained yet – and accuracy drops to 50–60%.
Level 3: LLM-based intents (powered by GPT)
This is where the magic happens. If the first two levels fail, the phrase goes to the LLM model, which interprets its meaning based on a simple instruction – for example, “detect whether the user likes dogs.” And it works. Even if a user says something like, “I like animals that go woof-woof, and I don’t like kittens,” GPT recognises this as a preference for dogs.
This architecture allows us to catch even those phrases that were never included in training. Thanks to the three levels, we now cover almost the full range of user expressions – from standard patterns to the most unexpected wordings.
And most importantly – it all happens nearly instantly. The user doesn’t feel any transitions between levels – to them, it’s simply “a bot that understands.
A real example: dogs, cats, and an unexpectedly smart dialogue
To demonstrate how the new system works, we created the simplest example: the bot asks the user – “Do you like dogs or cats?”
The script is set up for two intents:
- the user likes dogs
- the user likes cats
The intents are not trained – they only contain a couple of example phrases: “I like dogs,” “Dogs,” “I like cats,” “Cats.”
In the first call, the user says:
“I like dogs” – and the bot recognises the phrase without error, thanks to the first level (strict match).
But then we start to make things more difficult and test the bot with phrases it hasn’t seen before – more complex responses. For example
“I really prefer dogs” “I like animals that go woof-woof”
And each time, the bot understands the meaning – thanks to the LLM, when the GPT function is enabled. The bot replies
“Okay, I understand you like dogs.”
The bot even handles phrases where both animals are mentioned:
“I like dogs more than cats” “Dogs are better than cats, to be honest”
This matters because a typical keyword-based system would likely get confused, since both intents are present in the phrase. GPT, on the other hand, can detect priority, emotional tone, generalisations and even irony.
Let’s take a look at our examples in this video:
Real case: a launch in Serbia without testing – and with 100% accuracy
Demonstrations are great – but we wanted to see how our new approach to bot configuration would perform in real-world conditions. That opportunity came when we were launching a new bot in Serbia – using a language that was completely new to us.
We had a local partner and developed a bot for their client. Everything went as usual: script, intents, test phrases. But we deliberately skipped the steps that were previously considered mandatory:
- no technical team involved in tuning,
- no native speakers testing the bot,
- no endless Excel files with collected phrases.
Yes, we did a couple of basic test calls with our partner to check the logic, but that was it. The bot was delivered to the client as a demo – and they made exactly three test calls.
That’s important: clients typically make two to five test calls, and that’s enough for them to form an opinion. Our bot contained five intent-driven questions – already a fairly complex structure. Normally, properly training five intents takes several days of work and multiple iterations.
This time, however, the bot with the new three-level recognition approach handled all three calls without a single recognition error. Across the 15 intent-relevant phrases used during these calls, the bot identified all 15 correctly.
An hour later, the client said: “All looks great – let’s move on to full deployment.”
And that was a true turning point.
What we achieved in the end: a smart bot is not just about speed – it’s about quality of interaction too
Despite saving at least two weeks of work, we reached 94–99% accuracy in understanding user intents on day one – without any prior training of intents and without repeated iterations.
This wasn’t just optimisation – it was a qualitative leap in efficiency. And the client felt it: literally the next day after the launch, they approved a full-scale deployment.
Take a look at the recognition quality:
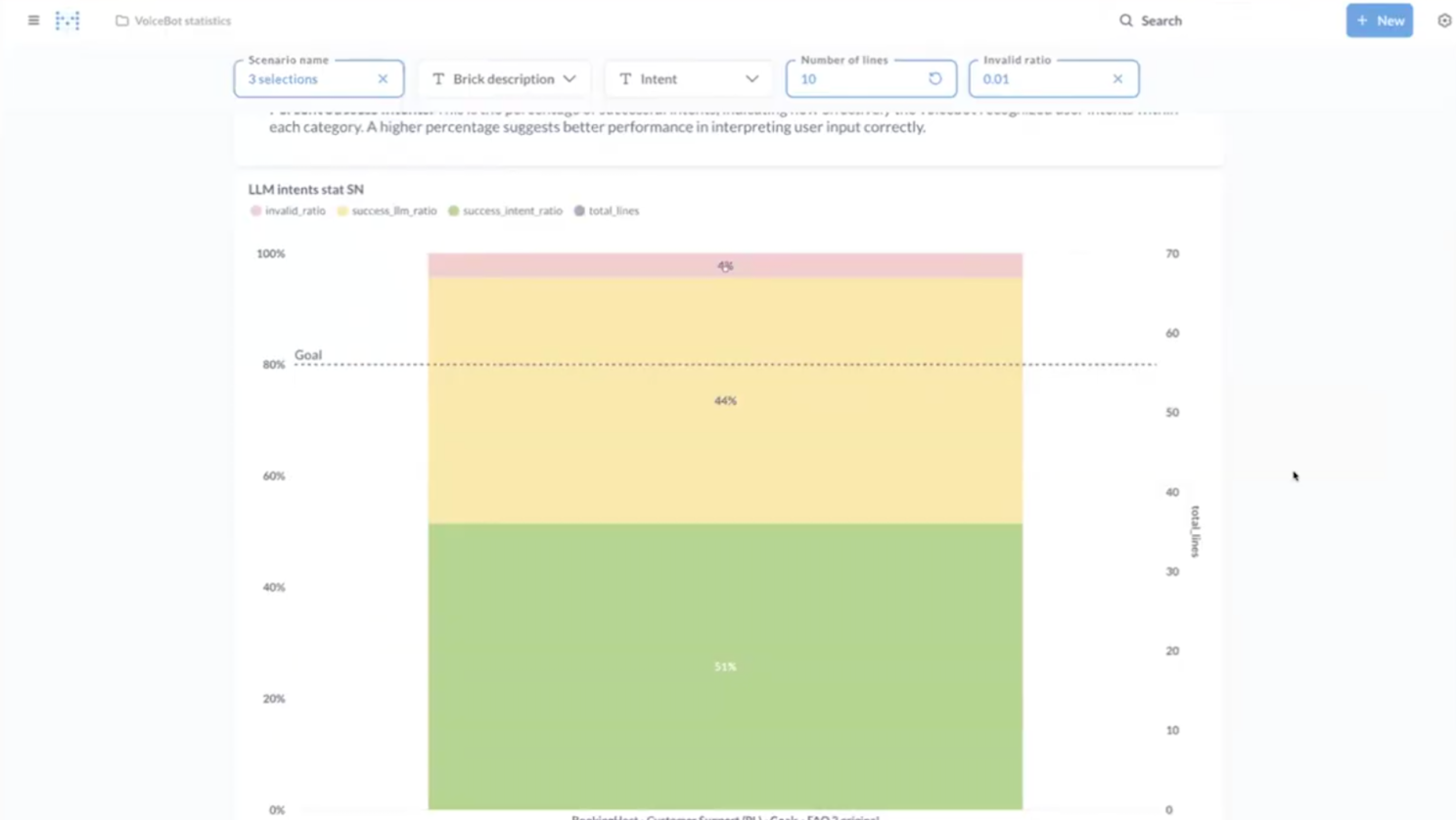
Green marks intents recognised on the first and second levels (the standard system);
Yellow marks those detected through the three-level architecture with GPT;
Red indicates errors (unrecognised phrases).
Apifonica AI-voicebot chart success process
Now there’s no need to guess how users will phrase their thoughts. It doesn’t matter whether they say “I’ve got a problem with the printer”, “It’s not printing”, or “Some paper issue again” – the bot understands. Because behind it, there’s not just a keyword, but genuine meaning recognition powered by LLM.
When the bot understands what the user wants – even if it’s expressed in an unusual or emotional way – that means:
- fewer repetitions,
- fewer “let me speak to a human”,
- less robotic behaviour – and more human-centred interaction.
English, Polish, Spanish – and beyond?
One of the most common questions after any demo is: “Does it work in other languages?” The short answer is – yes. In practice, we’ve tested this approach in five languages so far: English, German, Polish, Russian, and Serbian.
In all of them, GPT-based intents worked reliably and accurately. Even without prior training or custom phrase adaptation for the specific language, the system was able to recognise meaning, emotional context, and user preferences.
Setting up intents with GPT delivers excellent results – and theoretically, it should work just as well in many other languages.
Conclusion: true understanding by an AI-powered voicebot
Introducing the three-level intent recognition system has been a genuine breakthrough for us. We've moved past the fear of those crucial "first calls" and eliminated the exhausting cycles of training, testing, and retraining. Now, voicebots can go live almost immediately – even in a new language, with no prior setup, in a seamless way.
By integrating GPT, we’ve gone far beyond rigid phrase matching and moved towards true user understanding – recognising emotion, nuance, and unexpected ways of speaking. It’s not just about saving time and resources; it’s about delivering a fundamentally better user experience.
We believe this approach represents the future of voice-based interactions and enhances customer experience. And we’re more than happy to share what we've learned – to push the entire industry forward.
PS. Book a chat with our expert to explore Apifonica Global products. It’ll be interesting – we promise!